Relaxed – nový validátor XHTML kódu
Obsah
Související




Vytvořit po všech stránkách kvalitní webovou prezentaci není nic jednoduchého. Je potřeba zvládnout a dobře navrhnout grafický design stránky, navigaci a strukturu celého webu. Přitom navíc respektovat zásady tvorby přístupných a použitelných stránek. Za zcela samozřejmé se dnes považuje, že samotný kód HTML/XHTML stránek je korektní a je v souladu s některým doporučením W3C (nejčastěji HTML 4.01 nebo XHTML 1.0).
Mnoho věcí souvisejících s návrhem webu je spíše otázkou citu a vkusu a těžko se dá objektivně posuzovat. Jednou z mála věcí, kterou lze na první pohled zjistit velice snadno, je syntaktická správnost samotného XHTML kódu stránky. Snad každý vzdělanější tvůrce stránek zná validační službu W3C, která umožňuje zkontrolovat validitu stránky. Nástroj je to velice užitečný a zvláště začínající tvůrce stránek může upozornit na chyby v jejich kódu. Problém validátoru W3C je v tom, že za validní stránku může označit i stránku, která není v souladu s doporučeními W3C. Jak je to možné?
Validita versus shoda s normou HTML
Norma jazyka HTML definuje, jak má stránka zapsaná v jazyce HTML vypadat, jaké elementy a atributy lze používat a jak je zpracovávat, jaké hodnoty mohou obsahovat a podobně. Ověřit, zda nějaká stránka normě HTML vyhovuje, by znamenalo pečlivě zkontrolovat, zda není porušeno nějaké omezení napsané v textu normy HTML. To je samozřejmě dost nepohodlné a pomalé a navíc tento proces musí realizovat člověk, protože je potřeba interpretovat text normy a aplikovat jej na konkrétní stránku, kterou chceme zkontrolovat.
Aby šlo alespoň část kontroly shody s normou provádět automatizovaně, bývá zvykem pravidla zapsaná v textu normy nějakým způsobem formalizovat. V případě jazyka HTML (respektive XHTML) se využívá toho, že je odvozen od obecného značkovacího jazyka SGML (respektive XML) pomocí Document Type Definition (DTD). Jednoduchá syntaxe DTD umožňuje vyjmenovat, jaké elementy se mohou v dokumentu vyskytovat, jak se mohou navzájem skládat a jaké atributy lze u jednotlivých elementů použít. Validace stránky pak není nic jiného, než kontrola toho, zda vyhovuje všem pravidlům definovaným v DTD. Validátor W3C tak načte vaši stránku, zjistí vůči jakému DTD (verze, Strict/Transitional/Frameset) ji má validovat a přehledně vypíše seznam nalezených chyb nebo radostnou zprávu o tom, že je stránka validní.
Bohužel vyjadřovací prostředky DTD jsou poměrně omezené, a tak se poměrně mnoho z omezení popsaných v normě HTML nedá nijak převést do DTD. Jak se můžete sami přesvědčit, následující testovací stránka validátorem bez problémů projde.
<?xml version=’1.0′ encoding=’utf-8′?>
<!DOCTYPE html PUBLIC ‚-//W3C//DTD XHTML 1.0 Transitional//EN‘ ‚http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd‘>
<html xmlns=’http://www.w3.org/1999/xhtml‘>
<head>
<title>Stránka demonstrující nedostatky validátoru W3C</title>
</head>
<body>
<h1>Testování datových typů</h1>
<table border=’10%‘>
<tbody>
<tr>
<td>A</td>
<td><font color=’růžová‘>B</font></td>
</tr>
</tbody>
</table>
<h1>Vnořené formuláře</h1>
<form action=’process.form‘>
<div>
<form action=’process.subform‘>
<p>Něco je špatně</p>
</form>
</div>
</form>
<h1>Shoda NAME a ID</h1>
<form name=’form1′ id=’form2′ action=’process.form‘>
<p>Něco je špatně</p>
</form>
</body>
</html>
Při pozorném čtení však zjistíme, že kód rozhodně není v souladu s normou XHTML. Stránka obsahuje následující prohřešky:
- Atribut
borderobsahuje hodnotu10%. Podle specifikace však může obsahovat jen celé číslo, nikoli procenta. - Atribut
colormá hodnoturůžová. Podle specifikace však může tento atribut obsahovat jen číselný kód barvy nebo anglické jméno jedné ze šestnácti určených barev. - V druhé části stránky je do elementu
formvnořen další elementform. To je však opět v rozporu s normou. - U posledního formuláře jsou použity atributy
nameaidobsahující různé hodnoty (form1aform2). Přitom podle normy musí mít v tomto případě stejnou hodnotu.
Všechny tyto chyby prošly validací bez povšimnutí, protože vyjadřovací prostředky DTD jsou příliš omezené. Měli bychom si proto odnést důležitý poznatek, že validní stránka nemusí plně vyhovovat specifikaci HTML.
Moderní validační jazyky
Je zřejmé, že nikdy asi nebude možné formálně zapsat všechny detailní požadavky roztroušené ve volném textu specifikace. Nicméně naše ukázková stránka obsahuje chyby, které by šlo celkem snadno automaticky odhalit za předpokladu, že by DTD umožňovalo pro obsah atributů určit jejich datový typ a kontrolovat vztahy mezi hodnotami atributů. Tyto požadavky jsou při validaci poměrně časté, a proto vznikaly jazyky, které se snažily omezení DTD překonat. Pro popisování přípustné struktury dokumentů se dnes jako nejsilnější jeví kombinace jazyků RELAX NG a Schematron.
Jazyk RELAX NG umožňuje oproti DTD u jednotlivých elementů i atributů určit jejich datový typ. Můžeme tak snadno říci, kde má být v dokumentu číslo, kde datum a kde třeba libovolný textový řetězec. Pro elementy a atributy lze definovat i regulární výrazy, kterým mají vyhovět. Máme tak v ruce velmi silný nástroj, který dokáže dokument prověřit mnohem důkladněji než DTD.
Jazyk Schematron je velice speciální validační jazyk, který umožňuje definovat sadu podmínek, jimž musí dokument vyhovět. Podmínky se přitom zapisují pomocí dotazovacího jazyka XPath, který nabízí široké možnosti výběru a zpracování dat nacházejících se v dokumentu XML a zvládne i jednoduché výpočty.
Ani RELAX NG, ani Schematron nepocházejí z dílny W3C, ale jedná se o normy přijaté standardizačními organizacemi OASIS a ISO. I přesto si je jejich síly vědomo také mnoho lidí z W3C a nové návrhy W3C tyto jazyky používají. Například návrh XHTML 2.0 kromě DTD obsahuje i schéma standardu XHTML 2.0 v RELAX NG. (Chcete-li se rychle seznámit se základy těchto moderních validačních jazyků, můžete si přečíst tutoriál o XML schématech.)
Validátor Relaxed
Sílu validačních jazyků RELAX NG a Schematron využívá nový validátor Relaxed (http://badame.vse.cz/validator/), jehož autorem je Petr Nálevka. Petr prošel normy HTML a WCAG (přístupnost) a vytvořil schémata pro RELAX NG a Schematron, která mají za cíl automaticky kontrolovat co nejvíce omezení vyplývajících z těchto norem. Navíc vytvořil webovou aplikaci, která umožňuje snadnou validaci stránek.
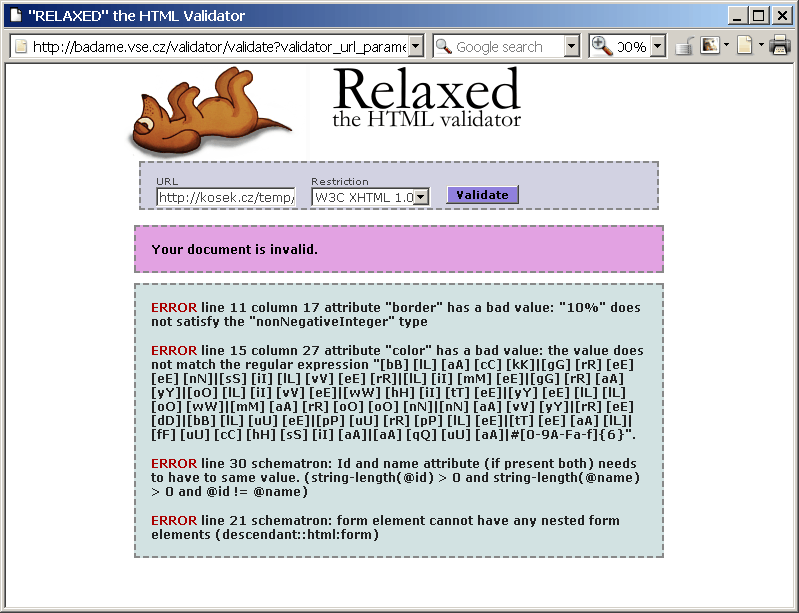
Na naší testovací stránce validátor Relaxed samozřejmě všechny dříve zmíněné chyby najde.

Relaxed díky využití moderních validačních nástrojů hravě odhalí i chyby, kterých se validátor W3C nevšimne (plná velikost, cca 25 kB)
Před validací si můžeme vybrat, zda se má stránka kontrolovat jen vůči pravidlům XHTML, nebo také vůči WCAG. Validátor přitom sám rozezná, zda se má validovat vůči variantě Strict, Transitional nebo Frameset. Validátor zpracuje i stránky v HTML, ale pro potřeby validace si je nejprve vnitřně převede na XHTML. Při tomto převodu ovšem mohou validátoru uniknout některé chyby, jako překřížené nebo neukončené elementy.
Zajímají-li vás podrobnosti o implementaci validátoru, bude nejlepší, když si přečtete bakalářskou práci, která vše podrobně popisuje. Narazíte-li při pokusech s Relaxed na nějakou chybu, nahlaste ji, prosím.
Mimochodem, validátor Relaxed si můžete nainstalovat také přímo na svůj počítač a spouštět jej z příkazové řádky, protože jsou k dispozici zdrojové kódy celé aplikace.
Souhrn
Validátor Relaxed v současné době nenabízí tolik funkcí jako validátor W3C a nemá tak propracovaná „lidsky čitelná“ chybová hlášení. I přesto bych vám doporučil jej používat. Zvalidujete-li si stránky zároveň pomocí Relaxed i validátoru W3C, budete mít mnohem větší jistotu, že vaše stránky vyhovují příslušným normám. A zároveň už víte, že ta jistota nebude nikdy stoprocentní.
Starší komentáře ke článku
Pokud máte zájem o starší komentáře k tomuto článku, naleznete je zde.









{kind=link}
erik
Kvě 9, 2010 v 9:32dobry den chceli sme vas zoner photo studio ale musim to kod heslo tak prosim poslimi jo dik
Miroslav Kucera
Kvě 9, 2010 v 12:38Kod ziskate zde: http://www.zoner.cz/objednavka/photo-studio-professional.asp