Redakční systém pro každého 1.



Publikujete v internetu nebo v intranetu a nemáte na drahý redakční systém? Podle dnes začínajícího seriálu článků si ho budete moci snadno udělat.
Vytvořený redakční systém bude umět vést databázi autorů, kteří budou mít možnost vkládat jednotlivé články. Samozřejmostí bude možnost zařazování jednotlivých článků do rubrik, které si vytvoříte. Autor bude moci vložit článek, ale pouze šéfredaktor ho schválí a vydá. Nebude chybět správa honorářů a čtenost jednotlivých článků. Redakční systém umožní zasílat čtenářům (na jejich přání) informace o nových článcích. Snadno bude možné doplnit systém o diskuzi a anketu ke každému článku, nebo umožnit čtenářům článek oznámkovat.
Ze zákulisí
Informace určené pro publikování budou uložené v databázi. Nedoporučuji ale použít jako databázovou základnu Microsoft Access, která je nevhodná pro použití v Internetu. Access je stavěna jako jednouživatelská a Internet je prostředí, ve kterém nikdy předem neznáte počet uživatelů aplikace. Při velkém počtu návštěvníků jsou jednotlivé požadavky na práci s databází řazeny do fronty, která se naplní natolik, že server přestane na další požadavky návštěvníků reagovat. Tím se celý váš web stane nedostupný.
Z těchto důvodů bude celý redakční systém konstruován pro provoz nad databázovým systémem Microsoft SQL Server. Všechny SQL dotazy jsou testovány pod SQL 7.0 a měli by být bez problémů funkční i pod verzí vyšší. Řada funkcí redakčního systému bude realizována pomocí uložených procedur přímo na SQL serveru. Výhodou tohoto řešení je vyšší rychlost a při vhodném nastavení přístupových práv i bezpečnost celého systému.
Redakční systém bude obsluhován pomocí webového rozhraní a bude konstruován pro bezproblémový provoz na webhostingu. Veškeré ASP skripty jsou psány tak, aby bez problémů fungovaly na Internet Information Server 4.0. Pusťme se tedy do práce. Nejdříve si připravíte databázovou základnu.
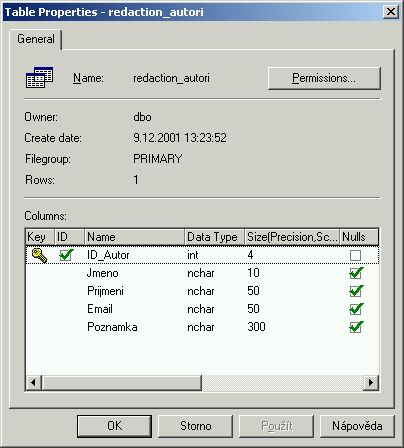
Přehled autorů
Tabulka pro udržování informací o autorech bude obsahovat jméno a příjmení autora, jeho e-mail, heslo pro přístup do redakčního systému a poznámky o autorovi.
CREATE TABLE [dbo].[redaction_autori] (
[ID_Autor] [int] IDENTITY (1, 1) NOT NULL ,
[Jmeno] [nchar] (10) COLLATE Czech_CI_AS NULL ,
[Prijmeni] [nchar] (50) COLLATE Czech_CI_AS NULL ,
[Email] [nchar] (50) COLLATE Czech_CI_AS NULL ,
[Poznamka] [nchar] (300) COLLATE Czech_CI_AS NULL
) ON [PRIMARY]
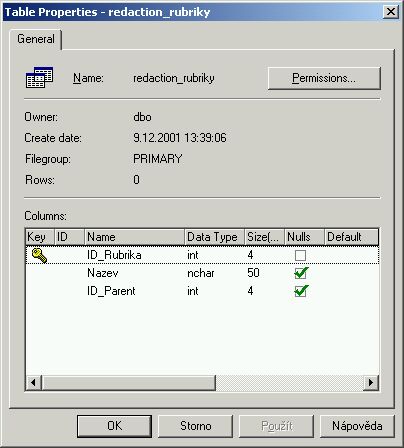
Rubriky a články
Do tabulky rubrik se budou ukládat definice jednotlivých rubrik webu. Tabulka je koncipována tak, aby bylo možné snadno, rychle a přehledně vytvářet strukturu webu.
CREATE TABLE [dbo].[redaction_rubriky] (
[ID_Rubrika] [int] IDENTITY (1, 1) NOT NULL ,
[Nazev] [nchar] (50) COLLATE Czech_CI_AS NULL ,
[ID_Parent] [int] NULL
) ON [PRIMARY]
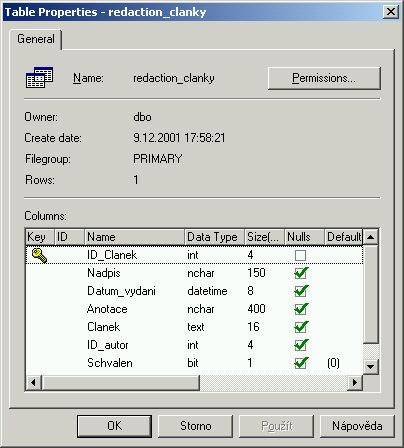
Také články budou mít svoji tabulku. Poté, co autor článek vloží do systému a označí ho jako hotový, obdrží šéfredaktor informaci o novém článku. Má možnost článek schválit (a určit datum vydání) nebo zamítnout. K zamítnutému článku pak může napsat svůj komentář.
CREATE TABLE [dbo].[redaction_clanky] (
[ID_Clanek] [int] IDENTITY (1, 1) NOT NULL ,
[Nadpis] [nchar] (150) COLLATE Czech_CI_AS NULL ,
[Datum_vydani] [datetime] NULL ,
[Anotace] [nchar] (400) COLLATE Czech_CI_AS NULL ,
[Clanek] COLLATE Czech_CI_AS NULL ,
[ID_autor] [int] NULL ,
[Schvalen] [bit] NULL ,
[ID_rubrika] [int] NULL
[Poznamka] COLLATE Czech_CI_AS NULL ,
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
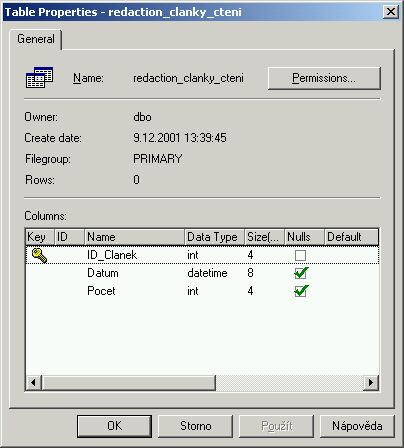
Tabulka čtení článků
Tato tabulka je určena pro sledování čtení jednotlivých článků. Údaje jsou do ní zapisovány tak, že z nich můžete získat statistiku četnosti článků po dnech. V případě požadavku na kratší časový interval musíte provést jednoduchou úpravu algoritmu pro zápis do tabulky.
CREATE TABLE [dbo].[redaction_clanky_cteni] (
[ID_Clanek] [int] NOT NULL ,
[Datum] [datetime] NULL ,
[Pocet] [int] NULL
) ON [PRIMARY]
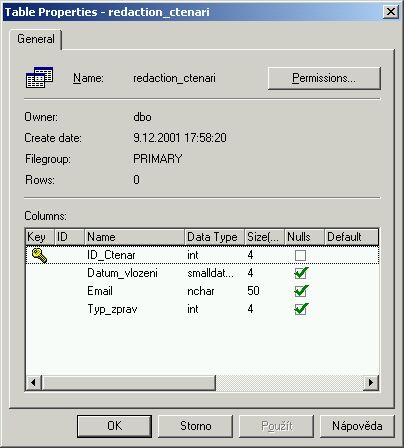
Tabulka čtenářů
Zde jsou archivovány údaje o čtenářích, kteří si přejí zasílat informace o nových článcích. Čtenář si může vybrat, v jakém formátu chce informace dostávat.
CREATE TABLE [dbo].[redaction_ctenari] (
[ID_Ctenar] [int] IDENTITY (1, 1) NOT NULL ,
[Datum_vlozeni] [smalldatetime] NULL ,
[Email] [nchar] (50) COLLATE Czech_CI_AS NULL ,
[Typ_zprav] [int] NULL
) ON [PRIMARY]
Indexy
Nyní sice máte hotové struktury tabulek, ale pro optimalizaci výkonu je třeba tabulky ještě vhodně indexovat. Pokud byste indexaci neprovedli, výkon celé aplikace bude značně omezený. Tabulku je vhodné indexovat alespoň podle unikátního klíče a podle položek používaných ke třídění nebo ke spojovaní s dalšími tabulkami.
Kromě položek „identity“, které jsou jako primární klíče v každé tabulce, je vhodné indexovat položky Datum_vydani,ID_autor,ID_rubrika
CREATE INDEX [index_redaction_clanky]
ON [dbo].[redaction_clanky]([Datum_vydani], [ID_autor],
[ID_rubrika]) ON [PRIMARY]
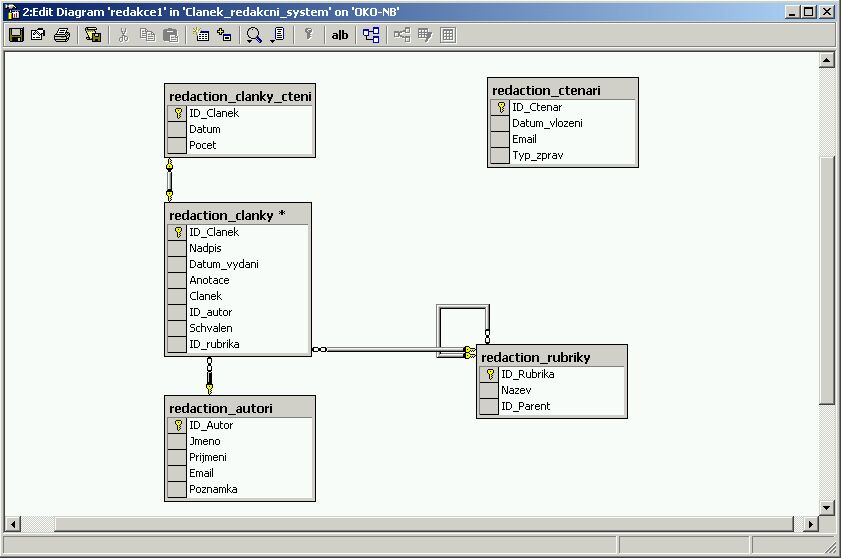
Vazby mezi tabulkami
Jednotlivé tabulky budou mezi sebou logicky svázané a společnými silami budou poskytovat informace nutné pro provoz redakčního systému. Na následujícím obrázku si můžete prohlédnout, jak budou jednotlivé vazby vypadat .
Celý redakční systém bude postaven tak, abych mohl reagovat na vaše požadavky. Pokud budete mít po přečtení tohoto dílu pocit, že vytvářenému redakčnímu systému něco chybí nebo přebývá, neváhejte to sdělit – např. v diskusním fóru pod tímto článkem.
Abych vam ulehčil práci s vytvořením databáze, připravil jsem ke stažení SQL skript pro vygenerovaní tabulek a vytvoření indexů. Skript si můžete stáhnout.
Starší komentáře ke článku
Pokud máte zájem o starší komentáře k tomuto článku, naleznete je zde.